
post by Edwina Abam (2019 cohort)
Introduction
The summer school programme I enrolled on during this year’s summer was the 3rd edition of the International Summer School Programme on Artificial Intelligence with the theme Artificial Intelligence from Deep Learning to Data Analytics (AI-DLDA 2020).
The organisers of the program were the University of Udine, Italy, in partnership with Digital Innovation Hub Udine, Italian Association of Computer Vision Pattern Recognition and Machine Learning (CVPL), Artificial Intelligence and Intelligent Systems National Lab, AREA Science Park and District of Digital Technologies ICT regional cluster (DITEDI).
Usually, the AI-DLDA summer school program is held in Udine, Italy, however, following the development of the COVID-19 situation, this year’s edition of the AI-DLDA summer school program was held totally online via an educational platform and it lasted for 5 days starting from Monday 29th June until Friday 3 July 2020. There were about 32 PhD students from over 8 different countries participating in the summer school as well as masters students, researchers from across the world and several industry practitioners from Italian industries and Ministers.
School Structure
The school program was organised and structured into four intensive teaching days with keynote lectures in the morning sessions and practical workshops in the afternoon sessions. The keynote lectures were delivered by 8 different international speakers from top universities and high profile organisations. Both lectures and lab workshop sessions were delivered via a dedicated online classroom.
Key Note Lectures and Workshops
Day 1, Lecture 1: The first keynote lecture delivered was on the theme, Cyber Security and Deep Fake Technology: Current Trends and Perspectives
Deep Fake Technology are multimedia contents which are created or synthetically altered using machine learning generative models. These synthetically derived multimedia contents are popularly termed as ’Deep Fakes’. It was stated that with the current rise in ’Deep Fakes’ and synthetic media content, the historical belief that images, video and audio are reliable records of reality is no longer tenable. The image in figure 1 below shows an example of Deep Fake phenomenon.
The research on Deep Fake technology shows that the deep fake phenomenon is growing rapidly online with the number of fake videos doubling over the past year. It is reported that the increase in deep fakes is sponsored by the growing ubiquity of tools and services that have reduced the barrier and enabled novices to create deep fakes. The machine learning models used in creating or modifying such multimedia content are Generative Adversarial Fusion Networks (GANs). Variants of the techniques include StarGANs and StyleGANs.

The speakers presented their own work which focused on detecting deep fakes by analyzing convolutional traces [5]. In their work they focused on the analysing images of human faces,by trying to detect convolutional traces hidden in those images: a sort of fingerprint left throughout the image generation process. They propose a new Deep fake detection technique based on the Expectation Maximization algorithm. Their method outperformed current methods and proved to be effective in detecting fake images of human faces generated by recent GAN architectures.
This lecture was really insightful for me because I got the opportunity to learn about Generative Adversarial Networks and to understand their architectures and applications in real-world directly from leading researchers.
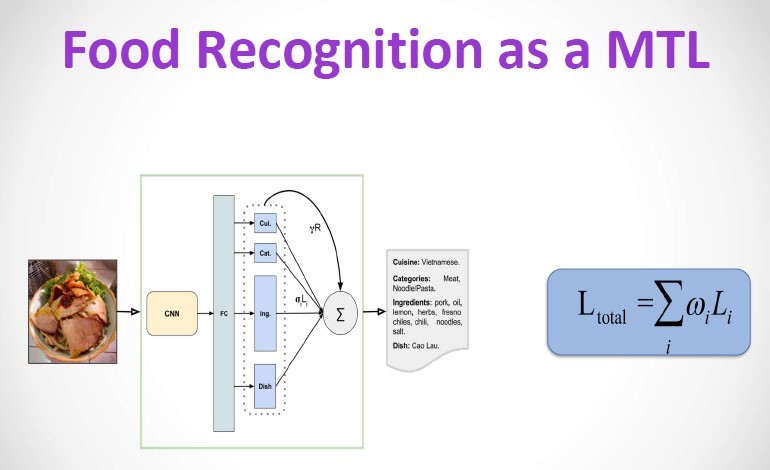
Day 1, Lecture 2: Petia Radeva from the University of Barcelona gave a lecture on Food Recognition The presentation discussed Uncertainty modeling for food analysis within end-to-end framework. They treated the food recognition problem as a Multi-Task Learning (MTL) problem as identifying foods automatically from different cuisines across the world is challenging due to the problem of uncertainty. The MTL Learning problem is shown in figure 2 below. The presentation introduced aleatoric uncertainty modelling to address the problem of uncertainty and to make the food image recognition model smarter [2].
Day 1, Lecture 3: The final keynote lecture on day 1 focused on Robotics, on the topic: Learning Vision-based, Agile Drone Flight: from Frames to Event Cameras which was delivered by Davide Scaramuzza from University of Zurich.
He presented on several cutting edge research in the field of robotics including Real time, Onboard Computer Vision and Control for Autonomous, Agile Drone Flight [3]. Figure 3 below shows autonomous drone racing from a single flight demonstration.

The presentation also involved an update of their curent research on the open challenges of Computer vision, arguing that the past 60 years of research have been devoted to frame based cameras, which arguably are not good enough. Therefore, proposing event -based cameras as a more efficient and effective alternative as they do not suffer from the problems faced by frame based cameras. [4]
Day 1, Workshop Labs: During the first workshop we had practical introduction to the Pytorch Deep Learning Framework and Google Colab Environment. This was led by Dott. Lorenzo Baraldi from University of Modena and Reggio Emilia.
Day 2, Lecture 1: Prof. Di Stefano, gave a talk on Scene perception and Unlabelled data using Deep Convolutional Neural Networks. His lecture focused on depth estimation by stereo vision and the performance of computer vision models against the bench marked Karlsruhe Institute of Technology and Toyota Technological Institute (KITTI) data set. He also discussed novel advancements in the methods used in solving computer vision problems such as Monocular Depth Estimation problem, proposing that this can be solved via Transfer learning. [10].
Day 2, Lecture 2: In addition, Prof. Cavallaro from Queen Mary University of London delivered a lecture on Robust and privacy-preserving multi-modal learning with body cameras.
Lab2 – Part I: Sequence understanding and generation still led by (Dott. Lorenzo Baraldi, University of Modena and Reggio Emilia)
Lab2 – Part II: Focused on Deep reinforcement learning for control (Dott. Matteo Dunnhofer, University of Udine)
Day 3, Lecture 1 keynote lecture focused on Self Supervision Self-supervised Learning: Getting More for Less Out of your CNNs by Prof. Badganov from University of Florence. In his lecture he discussed self-supervised representation learning and self-supervision for niche problems [6].
Day 3 lecture 2 was done by keynote speaker, Prof. Samek from Fraunhofer Heinrich Hertz Institute on a hot topic in the field of Artificial Intelligence on Explainable AI: Methods, Applications and Extensions.
The lecture covered an overview of current AI explanation methods and examples of real-world applications of the methods. We learnt from the lecture that AI explanation methods can be divided into four categories namely perturbation based methods, Function based methods, Surrogate based methods and Structure based methods. We learnt that structure-based methods such as Layer-wise Relevance Propagation (LRP) [1] and Deep Taylor Decomposition [7] are to be preferred over function-based methods as they are computationally fast and do not suffer the problems of the other types of methods. Figure 4 shows details of the layer-wise decomposition technique.
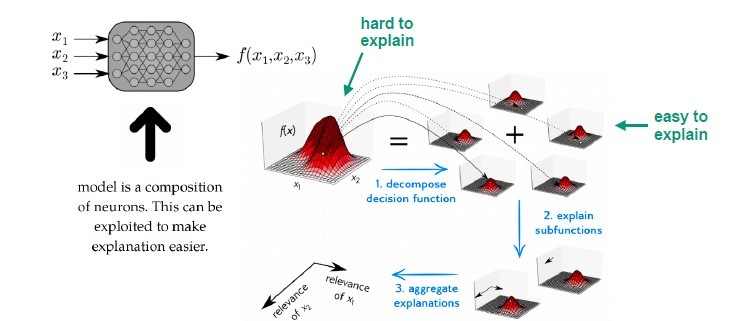
Overall, it was concluded that the decision functions of machine learning algorithms are often complex and analyzing them can be difficult. Nevertheless, levering the model’s structure can simplify the explanation problem. [9].
Lab3 – Part I: Lab 3 covered Going Beyond Convolutional Neural Networks for Computer Vision led by Niki Martinel and Rita Pucci from University of Udine
Lab3 – Part II: Going Beyond Convolutional Neural Networks for Computer Vision (Dott. Niki Martinel and Dott.ssa Rita Pucci, University of Udine)
Day 4: The final keynote lecture was done by Prof. Frontoni on Human Behaviour Analysis. This talk concentrated on the study of human behaviours specifically Deep Understanding of shopper behaviours and interactions using computer vision in the retail environment [8]. The presentation showed experiments conducted using different shopping data sets for tackling different retail problems including user interaction classification, person re-identification, weight estimation and human trajectory prediction using multiple store data sets.
The second part of the morning section on Day 4 was open for PhD students to present their research works to participants on the program.
Lab4 – Part I: Machine and Deep Learning for Natural Language Processing(Dott. Giuseppe Serra and Dott.ssa Beatrice Portelli , University of Udine)
Lab4 – Part II: Machine and Deep Learning for Natural Language Processing (Dott. Giuseppe Serra and Dott.ssa Beatrice Portelli , University of Udine)
Concluding Remarks
The summer school programme offered us the benefit of interacting directly with world leaders in Artificial Intelligence. The insightful presentations from leading AI experts updated us about the most recent advances in the area of Artificial Intelligence, ranging from deep learning to data analytics right from the comfort of our homes.
The keynote lectures from world leaders provided an in-depth analysis of the state-of-the-art research and covered a large spectrum of current research activities and industrial applications dealing with big data, computer vision, human-computer interaction, robotics, cybersecurity in deep learning and artificial intelligence. Overall, the summer school program was an enlightening and enjoyable learning experience.
References
- Sebastian Bach, Alexander Binder, Gr´egoire Montavon, Frederick Klauschen, Klaus-Robert Mu¨ller, and Wojciech Samek. On pixel-wise explanations for non-linear classifier decisions by layer-wise relevance propagation. PloS one, 10(7):e0130140, 2015.
- Marc Bolan˜os, Marc Valdivia, and Petia Radeva. Where and what am i eating? image-based food menu recognition. In European Conference on Computer Vision, pages 590–605. Springer, 2018.
- Davide Falanga, Kevin Kleber, Stefano Mintchev, Dario Floreano, and Davide Scaramuzza. The foldable drone: A morphing quadrotor that can squeeze and fly. IEEE Robotics and Automation Letters, 4(2):209–216, 2018.
- Guillermo Gallego, Tobi Delbruck, Garrick Orchard, Chiara Bartolozzi, Brian Taba, Andrea Censi, Stefan Leutenegger, Andrew Davison, J¨org Conradt, Kostas Daniilidis, et al. Event-based vision: A survey. arXiv preprint arXiv:1904.08405, 2019.
- Luca Guarnera, Oliver Giudice, and Sebastiano Battiato. Deepfake detection by analyzing convolutional traces. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, pages 666–667, 2020.
- Xialei Liu, Joost Van De Weijer, and Andrew D Bagdanov. Exploiting unlabeled data in cnns by self-supervised learning to rank. IEEE transactions on pattern analysis and machine intelligence, 41(8):1862–1878, 2019.
- Gr´egoire Montavon, Sebastian Lapuschkin, Alexander Binder, Wojciech Samek, and Klaus-Robert Mu¨ller. Explaining nonlinear classification decisions with deep taylor decomposition. Pattern Recognition, 65:211–222, 2017.
- Marina Paolanti, Rocco Pietrini, Adriano Mancini, Emanuele Frontoni, and Primo Zingaretti. Deep understanding of shopper behaviours and interactions using rgb-d vision. Machine Vision and Applications, 31(7):1–21, 2020.
- Wojciech Samek, Gr´egoire Montavon, Sebastian Lapuschkin, Christopher J Anders, and Klaus-Robert Mu¨ller. Toward interpretable machine learning: Transparent deep neural networks and beyond. arXiv preprint arXiv:2003.07631, 2020.
- Alessio Tonioni, Matteo Poggi, Stefano Mattoccia, and Luigi Di Stefano. Unsupervised adaptation for deep stereo. In Proceedings of the IEEE International Conference on Computer Vision, pages 1605–1613, 2017.