
post by Oliver Miles (2018 cohort)
Over three days from 12th-14th July 2021, I attended and participated in the Safe and Trusted Artificial Intelligence (STAI) summer school, hosted by Imperial College and Kings College London. Tutorials were given by leading academics, experts from British Telecom (BT) presented a session on industry applications, and I along with several other PhD students took part in a workshop speculating on AI interventions within the healthcare setting, presenting our work back to the wider group. In the following, I’ll summarise key contributors’ thoughts on what is meant by ‘safe and trusted’ in the context of AI and I’ll outline the themes and applications covered during the school I found to be most relevant to my own work. Two salient lessons for me expanded on contemporary efforts to reconcile accuracy with interpretability in models driving AI systems, and on efforts to systematically gauge human-human/human-machine alignment of values and norms, increasingly seen as critical to societal acceptance or rejection of autonomous systems.
When I read or hear the term ‘Artificial Intelligence’, even in the context of my peers’ research into present-day and familiar technologies such as collaborative robots or conversational agents, despite tangible examples in front of me I still seem to envision a future that leans toward science fiction. AI has always seemed to me to be intrinsically connected to simplistic, polarised visions of utopia or dystopia in which unity with some omnipotent, omniscient technology ultimately liberates or enslaves us. So, when it comes to considering STAI, I perhaps unsurprisingly default to ethical, moral, and philosophical standpoints of what a desirable future might look like. I obsess over a speculative AI’s apparent virtues and vices rather than considering the practical realities of how such futures are currently being realised and what my involvement in the process might mean for both me and the developing AI in question.
STAI began by addressing these big picture speculations as we considered the first theme – ethics of AI. According to AI professor Michael Rovatsos, ethical AI addresses the ‘public debate, impact, and human and social factors’ of technological developments, and the underlying values driving or maintaining interaction’ (2021). In a broad sense there was certainly agreement that ethical AI can and should be thought of as the management of a technology’s impact on contentious issues such as ‘…unemployment, inequality, (a sense of) humanity, racism, security, ‘evil genies’ (unintended consequences), ‘singularity’, ‘robot rights’ and so on (Rovatos, 2021). An early challenge however was to consider ethics as itself an issue to be solved; a matter of finding agreement on processes and definitions as much as specific outcomes and grand narrative. In short, it felt like we were being challenged to consider ethical AI as simply…doing AI ethically! Think ‘ethics by design’, or perhaps in lay terms, pursuing a ‘means justified end’.
To illustrate this, if my guiding principles when creating an AI technology are present in the process as much as the end product, when I think of ‘safe’ AI; I might consider the extent to which my system gives ‘…assurance about its behavioural correctness’; and when I think of ‘trusted’ AI; I might consider the extent of human confidence in my system and its decision making’ (Luck, M. 2021). A distinction between means and end – or between process and goal – appeared subtle but important in these definitions: While ‘assurance’ or ‘confidence’ appear as end goals synonymous with safety and trustworthiness, they are intrinsically linked to processes of accuracy (behavioural correctness) and explicability (of its system and decision-making rationale).
In her tutorial linking explainability to trustworthiness, Dr Oana Cocarascu, lecturer in AI at King’s College London, gives an example of the inclination to exaggerate the trustworthiness in some types of data-driven modelling that ‘…while mathematically correct, are not human readable’ (Cocarascu, O). Morocho-Cayamcela et al. (2019) demonstrate this difficulty in reconciling accuracy with interpretability within the very processes critical to AI, creating a trade-off between fully attaining the two end goals in practice (Figure 1).
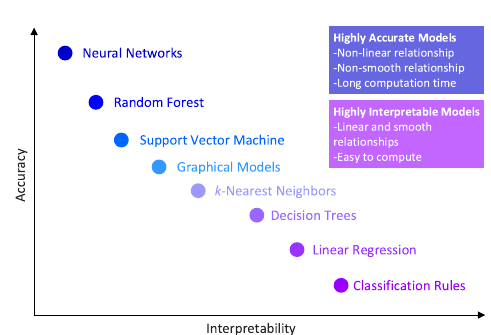
My first lesson for ‘doing AI ethically’ is therefore the imperative to demonstrate accuracy and explainability in tandem and without compromise to either. However, it doesn’t follow that this alone will ensure safe and trusted outcomes. A perfectly accurate and interpretable system may lead to confidence in mechanism, but what about confidence in an AI’s apparent agency?
In her tutorial ‘AI, norms and institutions’, Dr Nardine Osman talked about the ‘how’ of achieving STAI by means of harnessing values themselves. She convincingly demonstrated several approaches employing computational logic (e.g. ‘if-then’ rules) in decision making algorithms deployed to complex social systems. The following example shows values of freedom vs safety as contingent on behavioural norms in routine airport interactions expressed as a ‘norm net’ (Fig.2).
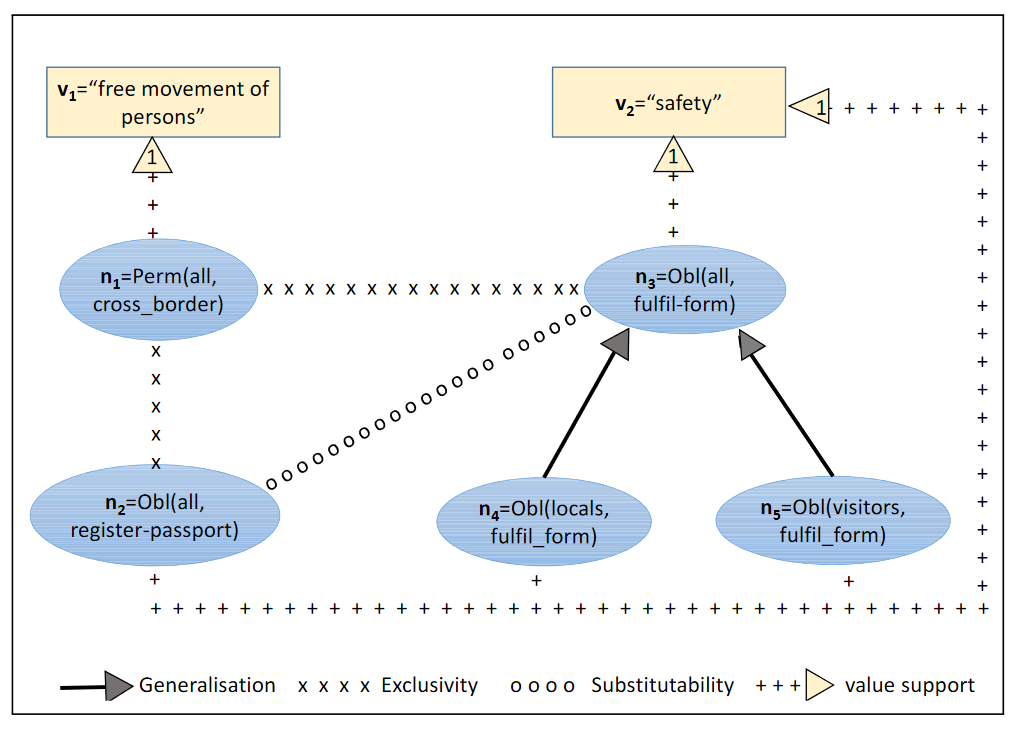
Serramia et al. visualise their linear approach to ethical decision making in autonomous systems, positioning conventionally qualitative phenomena – human values (e.g. safety) – as contingent on and supported by societal norms, e.g. of obligation to provide passports/forms (2018). Efforts to break down and operationalize abstract norms and values quantitatively (e.g. weighting by hypothetical preference, observed occurrence) demonstrate how apparent features of human agency such as situational discernment might become more commonplace in negotiating safe and trusted outcomes. My second lesson and main takeaway from STAI’21 was therefore the imperative of sensitising AI, and design of AI, to the nuances of social values – distinguishing between value preferences, end-goals, social norms and so forth.
Lastly and significantly, attending and participating in STAI’21 has given me invaluable exposure to the practicalities of achieving desirable AI outcomes. The focus on ‘doing AI ethically’ has challenged me to pursue safety, trustworthiness, and other desirable qualities in my own work – mechanistically in terms of ensuring explainability of my methods and frameworks; and substantively, in terms of novel approaches to conceptualising values and positioning against social norms.
References
Cocarascu, O (2021) XAI/Explainable AI, Safe and Trusted AI Summer School, 2021 https://safeandtrustedai.org/events/xai-argument-mining/
Luck, M (2021), Introduction, Safe and Trusted AI Summer School, 2021 https://safeandtrustedai.org/event_category/summer-school-2021/
Morocho-Cayamcela, Manuel Eugenio & Lee, Haeyoung & Lim, Wansu. (2019). Machine Learning for 5G/B5G Mobile and Wireless Communications: Potential, Limitations, and Future Directions. IEEE Access. 7. 137184-137206. 10.1109/ACCESS.2019.2942390.
Osman, N (2021) AI, Norms and Institutions, Safe and Trusted AI Summer School, 2021 https://safeandtrustedai.org/events/norms-and-agent-institutions/
Rovatsos, M (2021) Ethics of AI, Safe and Trusted AI Summer School, 2021 https://safeandtrustedai.org/events/ethics-of-ai/
Serramia, M., Lopez-Sanchez, M., Rodriguez-Aguilar, J. A., Rodriguez, M., Wooldridge, M., Morales, J., & Ansotegui, C. (2018). Moral Values in Norm Decision Making. IFAAMAS, 9. www.ifaamas.org
